Home
Graphics
Threat Watch ByteDance Spider
If you run a web server chances are your sites traffic has been invaded by the unwanted vistors
know as ByteDance. If you look at your access log there's a good chance you have seen traffic such as this
right here.
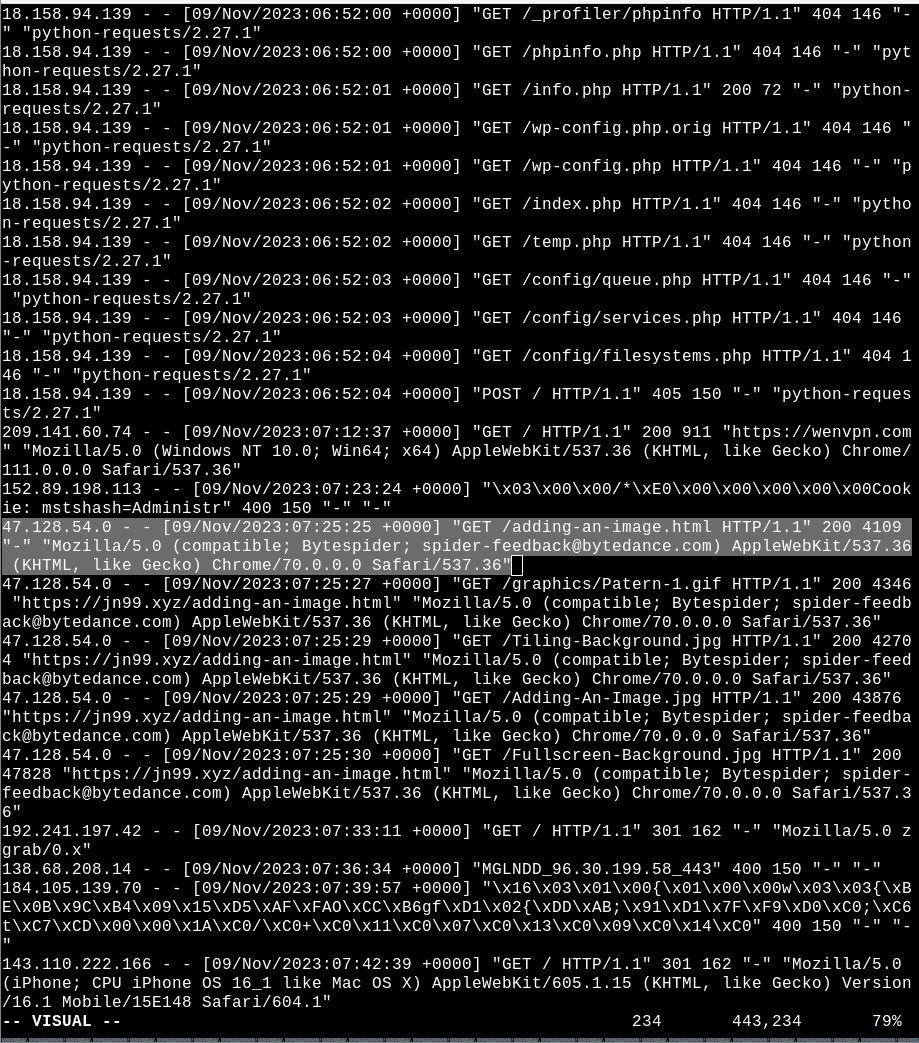
Who is ByteDance
ByteDance is a Chinese company who may or may not have ties to the CCP.
They also own the following products, CapCut, Douyin, Lark, Toutiao, Xigua Video, Nuverse,
and most infamously TikTok. Yes the same TikTok that has been all the rage over the last few years.
A few years ago the U.S. goverment tried to outright ban the platform due to concerns about its ties to
the CCP which only seemed to make the platform more popular. As a result of their growing popularity
they now site at the same table as the rest of big tech and are no different in their motives of spying,
collecting data, and selling that data to who ever wants it and yes they also track people who don't even use TikTok
through tracking pixels. Needless to say this is not an ethical company at all.
The ByteDance spider
Most webcrawlers or spiders as they are often called are search engines who place your site where ever they see fit
on their scale of relevance. ByteDance however is not a search engine in the sense that they point you to actual websites but
rather a few second videos to attempt to capitleize on the most revenue possible. With that in mind what exactly is
happening?
To truly understand how much of a pest this spider really is we first need to understand how bandwidth works
on a server. For each vistor your site draws in will generate a number of bandwidth per month. As that bandwidth builds up
it isn't uncommon to see slow downs on the website, increase of cost per month to run the site, and eventualy a Denial of Service
situation where no one can use the site.
Now with that in mind let's look at what ByteDance is doing. Esentualy they are running around trying to find what ever server they
can even if the admin has never used TikTok nor emabled any ads or tracking pixels and hunting down random pages for unknown reasons
although if anything about the ByteDances profile is anything to go off of it's probably not something good. Now with most web
crawlers you can set limitations on where they can and can't access pages from through something called robots.txt. The problem
is that ByteDance does not respect these limitions at all and will instead crawl through those pages anyway. And then there's
the bandwidth problem. These webcrawlers that ByteDance uses in the best way to describe it are freeloaders who not only
provide nothing of vaule but also activley hurt those who are effected by their actions.
Ok so it's one thing to eat up resources that could've gone to legitimate users, but if you actualy go on to
virustotal and do a lookup on these ip addresses that are comming from these webcrawlers you will find
that these are malicous ip addresses whos intentions are unknown.
Best course of action
If you are a user of site unfourtantly there really isn't a whole lot you can do to fight this
beast as it remains completly hidden to the end user even stuff like ublock origin don't seem to be able to find it.
The only thing you can do as the end user is to stop using products made by ByteDance such as TikTok and not installing it in
the first place which is becoming harder to do since most phones these days and even Windows 11 come with TikTok
preinstalled. Not to mention that unless you have a way of blocking all of ByteDances tracking pixels then they still
have your information and thus are still profiting off of you regaurdless of if you ever used their products or not.
If you are a server owner however you do have a few options please note that they may or may not work for you
so please do your own reasearch on the matter to find what works best for your services.
Option 1 is to disallow the offending company in the robots.txt file the downside to this approach though is
that it is possible for them to setup another spider with a different name so as to bypass the rules on the robots.txt file which
they already do not respect to begin with.
Option 2 you can try to block any associated ip addresses at the firewall level but the downside to this apporach is that
you would have to know every IP address these guys use in order to get rid of the spider and if know anything about
ip addresses you know that they can change at any given point meaning that this would only be temporary soluation to the
problem.